CLIP: Contrastive Language-Image Pre-training
Learning Transferable Visual Models From Natural Language Supervision
Takeaways
- CLIP consists of an image encoder (ResNet or ViT) and a text encoder (Transformer).
- CLIP is pre-trained to predict which caption goes with which image using contrastive learning.
- CLIP enables zero-shot transfer to other image classification task (using the class name as input text).
Introduction
The recent development of modern pre-training methods in NLP (e.g., T5
Using natural language supervision for image representation:
- Exciting as proofs of concept, but is still rare. This is likely because the performance on common benchmarks is much lower than SOTA.
- This line of work represents the middle ground between learning from a limited amount of supervised “gold labels” and learning from practically unlimited amounts of raw text.
- Compromise: use static softmax classifiers (fixed # of output classes) and lack a mechanism for dynamic outputs, which limits their “zero-shot” capabilities.
In this work, the authors
- create a new dataset of 400 million (image, text) pairs;
- demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch;
- transfer the model to downstream tasks in a zero-shot manner.
Methods
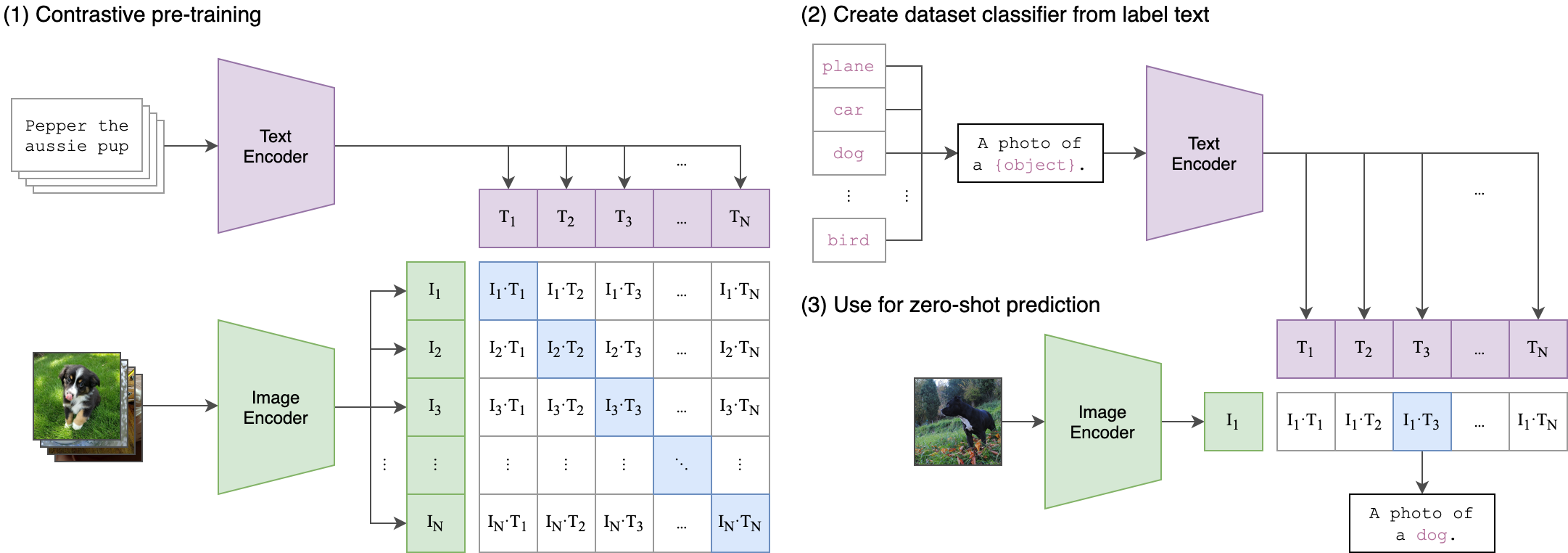
Summary of CLIP.
Natural Language Supervision
At the core of CLIP is the idea of learning perception from supervision contained in natural language.
Learning from natural language has several potential strengths over other training methods.
- Easier to scale natural language supervision compared to standard crowd-sourced labeling for image classification
- Learning from natural language also has an important advantage over most unsupervised or self-supervised learning approaches in that it doesn’t “just” learn a representation but also connects that representation to language which enables flexible zero-shot transfer.
Dataset
Create a new dataset: WebImageText (WIT)
- 400M image-text pairs,
- Collect from publicly available sources on the Internet,
- Search for (image, text) pairs whose text includes one of a set of 500,000 queries (frequent words in Wikipedia),
- Class balance the results by including up to 20,000 (image, text),
- The text data has a similar word count as the WebText dataset used to train GPT-2
.
Efficient Pre-Training Method
Initial Approach
Jointly train an image CNN and text transformer from scratch to predict the caption of an image.
Problem
This approach learns to recognize ImageNet classes three times slower than a much simpler baseline that predicts a bag-of-words encoding of the same text.
Reason
The models try to predict the exact words of the text accompanying each image. This is a difficult task due to the wide variety of descriptions, comments, and related text that co-occur with images.
Solution: Contrastive Representation Learning
Given a batch of \(N\) (image, text) pairs, CLIP is trained to predict which of the \(N\times N\) possible (image, text) pairings across a batch actually occurred.
To do this, CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the \(N\) real pairs in the batch while minimizing the cosine similarity of the embeddings of the \(N^2 - N\) incorrect pairings (see the pseudocode below).
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
CLIP was trained from scratch without initializing the image encoder with ImageNet weights or the text encoder with pre-trained weights.
Only used linear projection to map image/text representation to the multi-model embedding space (instead of non-linear projection)
Model
- Image encoder: ResNet / ViT
-
Text encoder: Transformer
Experiments
Zero-Shot Transfer
Zero-Shot Classification
Using class name as input text and predict the most probable pair (maximizing cosine similarity)
Results:
- CLIP outperforms Visual N-Grams.
- The best zero-shot CLIP model achieves an accuracy of 76.2% on ImageNet, matching the performance of the original supervised ResNet-50.
Prompt Engineering
The input texts during training are sentences while the label of an image is just a word. To help bridge this distribution gap, the authors use the prompt template "A photo of a {label}". Also, zero-shot performance can be significantly improved by customizing the prompt text for each task.
Representation Learning
Methods to evaluate the quality of learned representation:
- Fitting a linear classifier on the representation extracted from the model and measuring its performance on various datasets.
- Fine-tunning end-to-end
The first method is used in CLIP since fine-tuning end-to-end would change the representation and potentially mask some failures.
Robustness to Natural Distribution Shift
DL models are exceedingly adept at finding correlations and patterns which hold across their training dataset and thus improve in-distribution performance. However many of these correlations and patterns are actually spurious and do not hold for other distributions and result in large drops in performance on other datasets.
-
Effective robustness measures improvements in accuracy under distribution shift above what is predicted by the documented relationship between in-distribution and out-of-distribution accuracy.
-
Relative robustness captures any improvement in out-of-distribution accuracy.
Zero-Shot
Intuitively, a zero-shot model should not be able to exploit spurious correlations or patterns that hold only on a specific distribution, since it is not trained on that distribution.
Results show that zero-shot models can be much more robust, however, they do not necessarily mean that supervised learning on ImageNet causes a robustness gap. Other details of CLIP, such as its large and diverse pre-training dataset or use of natural language supervision could also result in much more robust models regardless of whether they are zero-shot or fine-tuned.
Fine-Tune on ImageNet
Although adapting CLIP to the ImageNet distribution increases its ImageNet accuracy by 9.2% to 85.4% overall, and ties the accuracy of the 2018 SOTA, average accuracy under distribution shift slightly decreases.
Flexible Classes
The target classes across the transfer datasets are not always perfectly aligned with those of ImageNet. With CLIP we can instead generate a custom zero-shot classifier for each dataset directly based on its class names.
Results: This improves average effective robustness by 5% but is concentrated in large improvements on only a few datasets.
Few-Shot
- Few-shot CLIP also increases effective robustness compared to existing ImageNet models.
- But few-shot CLIP is less robust than zero-shot CLIP.
- Minimizing the amount of ImageNet training data used for adaption increases effective robustness at the cost of decreasing relative robustness.
Limitations
- The zero-shot CLIP is on average competitive with the simple supervised baseline of a linear classifier on top of ResNet-50 features, and is well below the overall SOTA. Significant work is still needed to improve the task-learning and transfer capabilities of CLIP.
- The performance of CLIP is poor on fine-grained classification (e.g., differentiating models of cars), abstract and systematic tasks (e.g., number counting), and novel tasks which are unlikely to be included in the pre-training dataset.
- The zero-shot CLIP still generalizes poorly to data that is truly out-of-distribution for it. This suggests CLIP does little to address the underlying problem of brittle generalization of deep learning models. Instead, CLIP tries to circumvent the problem and hopes that by training on such a large and varied dataset that all data will be effectively in-distribution.
- CLIP is still limited to choosing from only those concepts in a given zero-shot classifier. This is a significant restriction compared to a truly flexible approach like image captioning which could generate novel outputs.
- CLIP also does not address the poor data efficiency of deep learning.
- Despite our focus on zero-shot transfer, we repeatedly queried performance on full validation sets to guide the development of CLIP.
- Many complex tasks and visual concepts can be difficult to specify just through text.
- CLIP does not optimize for few-shot performance directly, resulting in a counter-intuitive drop in performance when transitioning from a zero-shot to a few-shot setting. This is different from the human performance which shows a large increase from a zero to a one-shot setting.